김범수 기자
입력 : 2017.03.26 12:38
대학생 김영은(22) 씨는 발표 자료에 쓸 ‘페르시안 고양이가 야외에서 우유 마시는 사진’을 찾기 위해 ‘페르시안 고양이’를 검색했다. 김 씨는 약 1시간 동안 웹사이트를 뒤진 끝에 마음에 드는 자료를 찾았다.
직장인 최유현(35) 씨는 지난 주말 차를 운전해 교차로를 지나는 순간 좌측에서 빠르게 지나가는 차량과 충돌했다. 충돌 차량은 그대로 지나갔다. 블랙박스 화면에 차량이 찍혔지만 빠르게 지나가면서, 번호판은 물론 차종도 확인이 어려웠다. 최 씨는 사고 장소 주변 폐쇄회로화면(CCTV)을 확보하느라 며칠을 고생했다.

- ▲ 구글은 AI를 적용한 이미지 인식 기술을 위 사전처럼 이미지에서 사람이 인식할 수 없는 정보까지 얻어낼 수 있는 수준으로 끌어들이는 것이 목표다.
앞으로 구글의 인공지능(AI) 이미지 인식 기술의 발달로 이미지를 찾는 데 시간을 낭비하는 일이 획기적으로 줄어들 것으로 보인다. 구글은 딥러닝을 적용한 AI가 이미지를 학습하고 이미지의 모든 정보를 읽어낼 수 있게 만드는 것을 목표로 연구 중이다. 차가 달리는 사진에서 차종은 물론 연식과 위치까지 읽어낼 수 있게 하겠다는 것이다.
지난 22일 구글 코리아는 서울 강남구 본사에서 ‘구글 AI 포럼’을 열고 ‘AI 혁신과 구글 포토 들여다보기’를 주제로 현재 구글의 AI 이미지 인식에 대한 기술을 설명했다.
이날 화상 회의를 통해 기술 설명을 한 닐 알드린(Neil Alldrin) 구글 소프트웨어 엔지니어는 “구글 포토를 통해 인간을 뛰어넘는 ‘초 인간적 이미지 인식기술’을 달성하는 것이 목표”라고 말했다.
구글이 지금까지 연구한 이미지 인식 기술을 적용한 서비스가 ‘구글 포토’다. 2015년 5월부터 시작된 이 서비스는 구글 계정으로 로그인하면 사진 저장 용량을 무료로 무제한 사용할 수 있다. 모든 사진과 동영상을 보관하고 모든 기기에서 확인할 수 있어 관리가 쉽다. 특히 사용자가 보유한 수천장의 사진에서 원하는 사진을 찾기가 쉽다.
구글 포토는 사용자가 사진별로 태깅(tagging·특정 사진이나 게시물이 어떤 정보를 담고 있는지 사용자가 표시하는 것) 등으로 정보를 입력하지 않아도 특정 인물별로 사진을 정리해주거나 ‘생일’, ‘음식’, ‘수영’ 등 일반적인 단어로 검색하면 이에 맞는 사진을 찾는다. 쌓여있는 사진들 속에서 특정 시점이 기억나지 않더라도 필요한 사진을 찾아낼 수 있다.
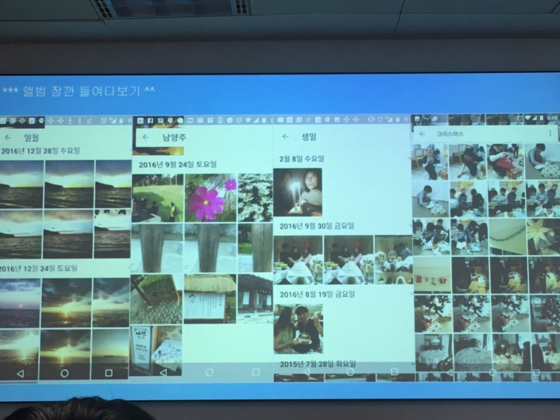
- ▲ 구글 포토를 통해 사용자가 가진 사진을 키워드별로 분류해서 검색해 보여준 화면. /김범수 기자
기존 컴퓨터는 이미지를 구성하는 ‘픽셀’을 인식하고 분석해 컴퓨터 값을 입력한다. 여기에 ‘고양이’로 인식될 평균값을 지정해주면 이 값에 가까운 요소들이 많은 이미지를 ‘고양이’로 인식하는 것이다.
구글은 여기서 더 나아가 딥러닝을 적용하고 평균값에서 벗어났지만 고양이 사진인 것과 평균값에 가깝지만 고양이 사진이 아닌것을 계속되는 이미지 학습을 통해서 걸러내거나 추가한다. 이를 위해 구글은 학습 알고리즘 구간에서 오류를 바로잡기 위한 더 많은 필터들이 추가되고 인식의 정확도를 올렸다.
구글이 이렇게 정교하게 만든 기술은 이미지가 가진 형태 만이 아니라 색상과 질감까지 구분해낼 수 있게 진화했다. 여기에 사진을 찍은 위치값이나 시점까지 학습해 특정 사진의 정보를 ‘라벨링(labeling)’한다.
닐 알드린 엔지니어는 “과거 라벨링은 별도의 작업을 해야했지만 딥러닝을 적용해 이미지를 학습하면서 저절로 라벨링을 할 수 있는 수준이 됐다”며 “이런 학습을 통해 구글 포토가 이미지를 인식하는데 사용하는 라벨링의 수준은 3년 전보다 25배 좋아졌다”고 말했다.
구글의 AI가 이미지를 계속해서 학습하고 ‘고양이’를 분류하는 것을 넘어 고양이의 ‘종’과 고양이의 ‘행동’까지 분류할 수 있게 됐다는 설명이다.
구글의 컴퓨터 비전이 AI로 학습하는 이미지 데이터는 ‘오픈 이미지 데이터셋’이라는 컴퓨터 비전 연구용 데이터셋을 이용한다. 900만개가 넘는 이미지로 구성된 이 데이터셋은 구글과 카네기맬론대, 코넬대가 공동으로 구축했다. 이중 10만개 정도의 이미지는 사람이 직접 해당 이미지가 어떤 내용을 담고 있는지를 라벨링하고 이를 바탕으로 AI가 학습을 한다. 다만 개인 사용자가 구글 포토 등을 통해 업로드한 사진은 사용하지 않는다는 것이 구글 측 주장이다.
구글 포토가 ‘생일’ 사진을 사용자의 사진 데이터에서 찾을 수 있는 것도 정교해진 딥러닝 알고리즘과 방대한 학습량 덕분이다. 생일과 연관된 사진을 학습하면서 해당 사진에는 케잌, 촛불, 생일 축하해(Happy Birthday) 글자 등이 있다는 것을 알게되고 이런 정보가 담긴 사진을 찾아내는 것이다.
닐 알드린 엔지니어는 “이미지에 담긴 정보를 인간만큼 읽어내는 것을 넘어 인간이 인식하지 못하는 부분까지 인식하도록 하기 위해 노력중이다”라며 “앞으로 이미지가 가진 정보를 완벽하게 문장으로 만들어 읽어줄 수 있는 AI가 등장할 수도 있것”이라고 말했다.
원문보기:
http://biz.chosun.com/site/data/html_dir/2017/03/26/2017032600545.html?right_key#csidxa699a8c8be29654a4c046fca85ca173 
'IT·가전' 카테고리의 다른 글
| 비즈 르포] LG G6, 美 국방부도 인정한 내구성과 배터리 안전성 살펴보니 (0) | 2017.03.26 |
|---|---|
| SK하이닉스, 지난해 4Q 영업익 1.5조원…"수퍼 호황에 그룹 서열 상승까지 겹경사"(종합) (0) | 2017.03.26 |
| 삼성전자, LGD로부터 TV용 패널 70만대 공급 받을듯 (0) | 2017.03.26 |
| 위기의 도시바, 반도체 경영권까지 넘기나 (0) | 2017.02.15 |
| 반도체 슈퍼 호황..D램 '탄탄대로' (0) | 2017.02.15 |